From standard softmax attention to FlashAttention & FlashDecoding (Japanese)
Attention calculation is a key component in transformer models. This blog post explains how attention calculation is accelerated, starting from naive softmax attention to FlashAttention and FlashDecoding. This post is written in Japanese.
このブログポストでは attention 計算がいかに高速化されているのかを step-by-step で説明する。具体的には、標準的な softmax attention からスタートし、FlashAttention と FlashDecoding に至るまでを説明する。
ゴール

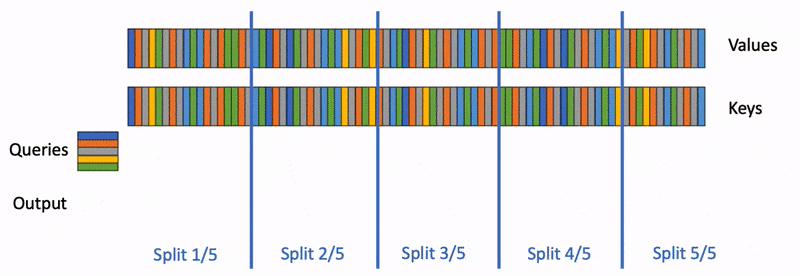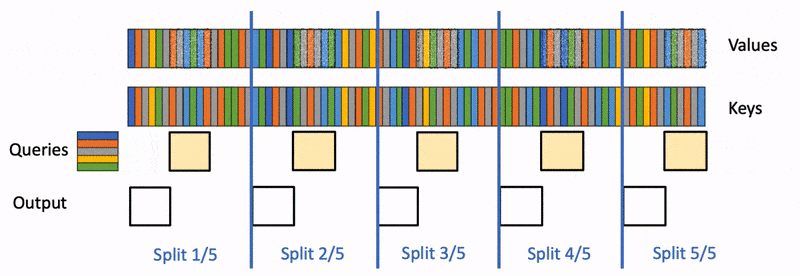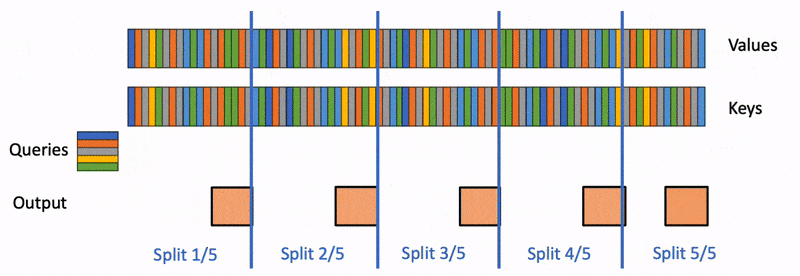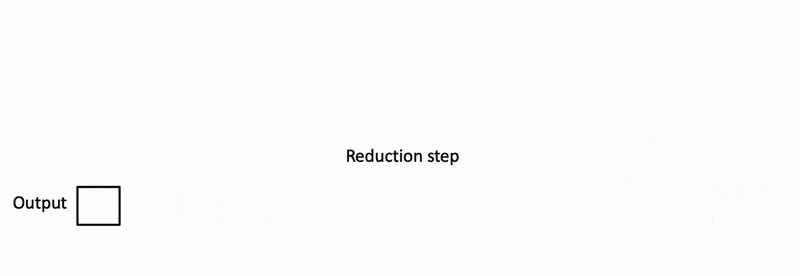
これを理解する。そのためには block-wise に分割した attention 計算を、うまくマージする方法を考えれば良い。
Attention 計算
Attention は query, key から attention score を計算し、そのスコアで value を重み付けして出力する。
- 入力: $\bf{Q}, \bf{K}, \bf{V} \in \mathbb{R}^{n \times d}$
- Attention 計算
- Softmax 前のスコア: $\bf{S} = \bf{Q} \bf{K}^T \in \mathbb{R}^{n \times n}$
- Attention score: $\bf{P} = \text{softmax}(\bf{S}) \in \mathbb{R}^{n \times n}$
- $\text{softmax}$ は行方向に softmax 計算を行う関数
- 出力: $\bf{O} = \bf{P} \bf{V} \in \mathbb{R}^{n \times d}$
GPU の memory hierarchy
WIP
Naive な softmax 計算
WIP
FlashAttention:
WIP
FlashDecoding: 系列長方向への並列化
WIP